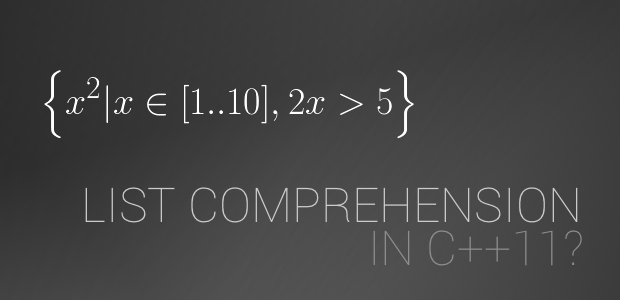
List comprehension in functional languages is the name of list constructor syntax, which is similar to set-builder notation from math.
What are the benefits of using list comprehension? One is readability, and the other one is the fact of decoupling iteration from actual construction. We could even hide parallel execution under the hood of list comprehension. Also by adding additional options to such declaration we could make the list construction a lot shorter.
If we look closer at list comprehension’s syntax, it will remind of one another very familiar thing – SQL select! Output expression, input set, predicates are equivalent to select, from, where sequence (of course not exactly, but they are very alike). Ok, let’s implement such syntax sugar using C++11 (without boost and LINQ-like libs).
You can skip implementation details and scroll to examples to see the result first.
SHORT IMPLEMENTATION
Let’s define whole operation as simple function which will produce vector<> of something.
|
1 2 3 4 5 6 |
template <typename R, typename... Args, typename... Sources, typename... Options> vector<R> select(std::function<R(Args...)> f, ///< output expression const std::tuple<Sources...>& sources, ///< list of sources const std::function<bool(Args...)>& filter, ///< composition of filters const Options&... options ///< other options and flags ) { ... } |
Feel the power of variadic templates. First argument is simple function and its declaration defines output type and input variables. The next argument is tuple of source containers and their number should be equal to number of output expression’s arguments. Third argument is composition of ‘where’ filters. The rest parameters are optional flags.
You would expect a lot of code as implementation but the core will be quite compact.
Let’s write main processing cycle:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
template<std::size_t I = 0, typename FuncT, typename... Tp, typename... Args> inline typename std::enable_if<I == sizeof...(Tp), bool>::type for_each_in_sources(const std::tuple<Tp...> &, FuncT& f, Args&... args) { return f(args...); } template<std::size_t I = 0, typename FuncT, typename... Tp, typename... Args> inline typename std::enable_if<I < sizeof...(Tp), bool>::type for_each_in_sources(const std::tuple<Tp...>& t, FuncT& f, Args&... args) { bool isFinished; for(auto& element : std::get<I>(t)) { isFinished = for_each_in_sources<I + 1, FuncT, Tp...>(t, f, args..., element); if (isFinished) break; } return isFinished; } // .... inside ..... vector<R> result; int count = 0; auto process = [&](const Args&... args){ if (filter(args...)) { result.push_back(f(args...)); count++; } return (count == limit); // isFinished }; for_each_in_sources(sources, process); |
This is quite strait-forward approach – we will go through all combinations of input elements performing simple ranged for cycles. So when using list comprehension the one should keep in mind that providing too vast input arrays will result in too slow computation time. For example, if we have 3 sources, complexity will be O(n^3). So i decided to add some minor protection here – limit of requested data (it is like LIMIT instruction inside SQL-request syntax). When the limit is reached – cycles will be aborted (but this anyway will not solve all possible conditions).
As for main working part – here we use template recursion over tuple of sources, performing a cycle on each step. If you are not familiar with such approach here is working sample of simple iteration over tuple elements.
All other stuff below is optional!
First additional thing to add is set of optional flags to setup query limit, sorting options and so on. For implementation of simple bool flags we would just use class enum from C++11, but if we want to set complex options (like manual sorting with compare function, etc) we could go with the following approach:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
class SelectOption { public: virtual bool imPolymorphic() { return true; } }; class SelectOptionLimit : public SelectOption { public: int limit; SelectOptionLimit(int limit) : limit(limit) {} }; class SelectOptionSort : public SelectOption {}; class SelectOptionDistict : public SelectOption {}; // ..... INSIDE select() ..... int limit = -1; bool isDistinct = false; bool isSorted = false; for_each_argument([&](const SelectOption& option){ if (auto opt = dynamic_cast<const SelectOptionLimit*>(&option)) { limit = opt->limit; }; if (dynamic_cast<const SelectOptionSort*>(&option)) { isSorted = true; }; if (dynamic_cast<const SelectOptionDistict*>(&option)) { isDistinct = true; }; }, options...); // .... HERE IS MAIN CYCLE .... // sort results if ((isDistinct) || (isSorted)) std::sort(result.begin(), result.end()); // remove duplicates if (isDistinct) { auto last = std::unique(result.begin(), result.end()); result.erase(last, result.end()); } |
Now our select has 3 additional options – limit, district and sort. Of course, we assume our result items to be comparable if we expect sort to work.
We can add additional declaration to be able to call select function without filters when we do not need them:
|
1 2 3 4 5 6 7 |
template <typename R, typename... Args, typename... Sources, typename... Options> inline vector<R> select(std::function<R(Args...)> f, const std::tuple<Sources...>& sources, const Options&... options) { return select(f, sources, to_fn([](Args... args){ return true; }), options...); } |
And to have fun let’s do some evil thing…
|
1 2 3 4 5 6 7 |
#define SELECT(X) select(to_fn(X), #define FROM(...) std::make_tuple(__VA_ARGS__) #define WHERE(...) ,fn_logic_and(__VA_ARGS__) #define SORT ,SelectOptionSort() #define DISTINCT ,SelectOptionDistict() #define LIMIT(X) ,SelectOptionLimit(X)) #define NOLIMIT LIMIT(-1) |
Aside from quite obvious shortcuts for function calls we are making two important conversions here. First – we are converting first function into std::function using to_fn(). This is equivalent to to_function() from my previous post about functional decomposition in C++ and AOP. In short, it’s equal to casting to std::function<..> with automatic detection of arguments types and return type.
Second thing is more interesting – fn_logic_and(…). This method is making one function from bunch of filter functions (to be provided as third argument into main list comprehension function). This is not classic composition of functions as we don’t have chained calls, but instead it’s like logical operation over list of functions. For implementation of fn_logic_and() look at post bottom. This function is optional – you can pass the filter functions as tuple and iterate over it or store them as vector.
Note that if we don’t want to make copies of sources (as std::make_tuple does it) we can switch to std::forward_as_tuple as the solution for passing tuple of references. But this might not be so safe. Anyway the approach itself does not require to copy the sources – you can use references or smart-pointers to pass sources (after minor modifications).
As final touch before getting something that works, we need source class for range of natural numbers (as the majority of list comprehension examples use integers). To use ranged for over this source, we need to implement Iterator inside.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
class Naturals { int min; int max; public: Naturals() : min(1),max(1000) {} Naturals(int min, int max) : min(min),max(max) {} int at(int i) const { return i + min; } ; int size() const { return max - min + 1; } ; class Iterator { int position; public: Iterator(int _position):position(_position) {} int& operator*() { return position; } Iterator& operator++() { ++position; return *this; } bool operator!=(const Iterator& it) const { return position != it.position; } }; Iterator begin() const { return { min }; } Iterator end() const { return { max }; } }; |
Note that by default the range is only [1..1000].
Ok, let’s have some fun.
EXAMPLES OF LIST COMPREHENSION
Let’s start from something trivial:
|
1 2 3 |
SELECT([](int x){ return x; }) FROM(Naturals()) LIMIT(10); // List: 1 2 3 4 5 6 7 8 9 10 |
We can implement map operation as list comprehension:
|
1 2 3 4 5 6 7 8 |
auto ints = {11,2,1,5,6,7}; SELECT([](int x){ return x + 5; }) FROM(ints) NOLIMIT; // List: 16 7 6 10 11 12 SELECT([](int x)->string { return x % 2 == 0 ? "BOOM" : "BANG"; }) FROM(ints) NOLIMIT; // List: 'BANG' 'BOOM' 'BANG' 'BANG' 'BOOM' 'BANG' |
Ok, time for filters. Let’s find matching elements inside two sets of integers (and sort them):
|
1 2 3 4 5 6 7 8 |
auto ints = {11,2,1,5,6,7}; auto ints2 = {3,4,5,7,8,11}; result = SELECT([](int x, int y){ return x; }) FROM(ints, ints2) WHERE([](int x, int y){ return (x == y); }) SORT NOLIMIT; // List: 5 7 11 |
Another example using DISTINCT:
|
1 2 3 |
SELECT([](int x, int y){ return x + y; }) FROM(Naturals(), Naturals()) WHERE([](int x, int y){ return (x*x + y*y < 25); }) DISTINCT LIMIT(10); // List: 2 3 4 5 6 |
Next example from Erlang guide on list comprehension – pythagorean triplets:
|
1 2 3 4 5 |
int N = 50; SELECT([&](int x, int y, int z){ return make_tuple(x,y,z); }) FROM(Naturals(1,N), Naturals(1,N), Naturals(1,N)) WHERE([&](int x, int y, int z){ return (x+y+z <= N); }, [&](int x, int y, int z){ return (x*x + y*y == z*z); }) LIMIT(N); |
Result:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
-> 3 4 5 -> 4 3 5 -> 5 12 13 -> 6 8 10 -> 8 6 10 -> 8 15 17 -> 9 12 15 -> 12 5 13 -> 12 9 15 -> 12 16 20 -> 15 8 17 -> 16 12 20 |
We could run select using custom data classes ( select id and name from users where id in [….] )
|
1 2 3 4 5 6 7 8 9 |
vector<User> users {make<User>(1, "John", 0), make<User>(2, "Bob", 1), make<User>(3, "Max", 1)}; auto ints = {11,2,1,5,6,7}; SELECT([](int x, User u){ return make_pair(u->id, u->name); }) FROM(ints, users) WHERE([](int x, User u){ return (u->id == x); }) LIMIT(10); // -> 2, Bob // -> 1, John |
We also can perform nested selects:
|
1 2 3 4 5 6 |
SELECT([](int x, int y){ return x*y; }) FROM( SELECT([](int x){return x;}) FROM(Naturals()) WHERE([](int x){ return x % 2 == 0; }) NOLIMIT, SELECT([](int x){return x;}) FROM(Naturals()) WHERE([](int x){ return x % 2 == 1; }) NOLIMIT ) SORT LIMIT(10); // Result: 2 6 10 14 18 22 26 30 34 38 |
Sure in haskell this will be a lot more compact, but, as you can see, it’s not as scary as expected from C++.
LAZY EVALUATION
If we want to make whole select lazy this can be done pretty easily:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
template <typename R, typename... Args, typename... Sources, typename... Options> std::function<vector<R>()> select_lazy( const std::function<R(Args...)>& f, ///< output expression const std::tuple<Sources...>& sources, ///< list of sources const std::function<bool(Args...)>& filter, ///< composition of filters const Options&... options ///< other options and flags ) { return to_fn([=](){ return select(f, sources, filter, options...); }); } #define LAZYSELECT(X) select_lazy(to_fn(X), auto get = LAZYSELECT([](int& x){ return x; }) FROM(ints) WHERE([](int& x){ return x % 2 == 0; }) LIMIT(20); LOG << "Evaluate it later... " << NL; auto result = get(); // evaluation |
Notice that function contains capture by value inside. This is optional choice. Anyway, if your ‘where‘ filters contain capture by reference of some additional parameters this could lead to undefined behaviour when is used out of scope. But this is general practice with lambdas.
There is nice post from Bartosz here about laziness, list comprehension and C++’s way to implement it from different angle. Here is described more strait-forward and thus more simple and clear way (it does not mean it’s better). We don’t wrap data and sources into something and so on, but implementation of laziness from Bartosz has one nice feature – it gives you ability to request results of query part by part as true lazy evaluation should do. Let’s add this feature into current scheme.
Let’s add new option, which will contain information about current request state. For more compact example it will just contain array of integer indexes (you can change it to Iterators if you want).
|
1 2 3 4 |
class SelectContinuation : public SelectOption { public: vector<int> indexes; }; |
When this option is provided, iterations over tuple of sources should be slightly altered:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
template<std::size_t I = 0, typename FuncT, typename... Tp, typename... Args> inline typename std::enable_if<I == sizeof...(Tp), bool>::type for_each_in_sources_indexed(const std::tuple<Tp...> &, FuncT& f, vector<int>& indexes, Args&&... args) { return f(args...); } template<std::size_t I = 0, typename FuncT, typename... Tp, typename... Args> inline typename std::enable_if<I < sizeof...(Tp), bool>::type for_each_in_sources_indexed(const std::tuple<Tp...>& t, FuncT& f, vector<int>& indexes, Args&&... args) { bool isFinished; int size = std::get<I>(t).size(); int i = indexes[I]; if (I != 0) if (i >= size) i = 0; if (i >= size) return false; for (; i < size; i++) { isFinished = for_each_in_sources_indexed<I + 1, FuncT, Tp...>(t, f, indexes, args..., std::get<I>(t).at(i)); if (isFinished) break; } indexes[I] = ++i; return isFinished; } |
We just changed cycle to indexed version. Function stores last iteration positions inside indexes[] array and starts from it when iteration is called again. One of options would be encapsulating this state inside select functor, but here we store state it inside outer option object. This is just one of possible ways.
Let’s change Pythagorean Triplets example… (this is not final version)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
// just for beauty #define LAZY(X) ,(X) SelectContinuation state; auto lazypyth = LAZYSELECT([&](int x, int y, int z){ return make_tuple(x,y,z); }) FROM(range, range, range) WHERE([&](int x, int y, int z){ return (x+y+z <= N) && (z > y) && (y > x); }, [&](int x, int y, int z){ return (x*x + y*y == z*z); }) LAZY(state) LIMIT(5); // Request 5 items... auto pyth = lazypyth(); // Output: -> 3 4 5 // -> 5 12 13 // -> 6 8 10 // -> 7 24 25 // -> 8 15 17 // Request 5 more items... pyth = lazypyth(); // Result: -> 9 40 41 // -> 10 24 26 // -> 11 60 61 // -> 12 16 20 // -> 12 35 37 |
Looks nice? But there is one major problem. Lazy evaluation could work with very large ranges of input data (even infinite ranges are fine in Haskell). If we provide Naturals(1,100000000) as input for our 3 variables in current example, the cycles will run forever… What to do to solve this? Many ways:
- we could recreate input sources before each iteration depending on current indexes of upper cycles
- we could wrap sources into classes which will provide method narrowing iteration range before each cycle
- we could provide additional restricting functions as options which will break inner cycles conditionally
The most flexible way is providing functions which will produce sources instead of forwarding sources themselves (as expected in functional world…). There is no problem to change implementation to handle such input, but i want add one more feature – i want to support both object sources and functions which will produces sources simultaneously. And even to be able to use them mixed in single request. And again, to implement this we could add relatively tiny layer of code (for C++):
Inside main cycles we add additional call to getSource() function to provide the source on each iteration. So now it looks like:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
template<std::size_t I = 0, typename FuncT, typename... Tp, typename... Args> inline typename std::enable_if< I < sizeof...(Tp), bool>::type for_each_in_sources_indexed(const std::tuple<Tp...>& t, FuncT& f, vector<int>& indexes, Args&&... args) { bool isFinished; auto&& src = getSource(std::get<I>(t), args...); int size = src.size(); int i = indexes[I]; if (I != 0) if (i >= size) i = 0; if (i >= size) return false; for (; i < size; i++) { isFinished = for_each_in_sources_indexed<I + 1, FuncT, Tp...>(t, f, indexes, args..., src.at(i)); if (isFinished) break; } indexes[I] = ++i; return isFinished; } |
And getSource() has conditional implementation depending on which source type it gets. The main problem here is how to identify that provided class is lambda function?
To do this we can use std::enable_if in couple with std::declval and std::is_object:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
template <typename Src, typename... Args> inline typename std::enable_if< std::is_object<decltype(std::declval<Src>().begin()) >::value, Src&&>::type getSource(Src && src, Args&&... args) { return std::forward<Src&&>(src); } template <typename F, typename... Args, typename FRes = decltype(std::declval<F>()(std::declval<Args>()...))> inline typename std::enable_if<std::is_object< decltype(std::declval<F>()(std::declval<Args>()...)) >::value, FRes >::type getSource(F && f, Args&&... args) { return std::forward<FRes>(f(std::forward<Args>(args)...)); } |
First variant checks that object has begin() method. If it has it – it’s raw object. Second variant just attempts to get result type of possible function call. Luckily we can just pass the list of arguments as variadic template.
Let’s test it:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
auto lazypyth = LAZYSELECT([&](int x, int y, int z){ return make_tuple(z,y,x); }) FROM(Naturals(1,100000000), [](int x){ return Naturals(1,x); }, [](int x,int y){ return Naturals(1,y); }) WHERE([&](int x, int y, int z){ return x*x == y*y + z*z; }) LAZY(state) LIMIT(5); lazypyth(); // Result: // -> 3 4 5 // -> 6 8 10 // -> 5 12 13 // -> 9 12 15 // -> 8 15 17 lazypyth(); // Result: // -> 12 16 20 // -> 15 20 25 // -> 7 24 25 // -> 10 24 26 // -> 20 21 29 |
We had to change the order of parameters and now it works fast enough (enough for not optimised example code).
Note: the same way you can extend select to support different types of sources. For example, wrapped inside shared_ptr<>, etc.
Also note that after all modifications this is still just simple function. All macros are optional and you could use select() as normal function.
HOW ABOUT CONCURRENCY?
Making acceptable assumptions that our sources are safe to iterate over at the same time, there will be no problem to extend our sample to support concurrent execution! We can slightly modify continuation option, which we used for laziness by adding special constructors. This will allow us to manually set iteration start indexes as job parameters.
|
1 2 3 4 5 6 7 |
class SelectContinuation : public SelectOption { public: vector<int> indexes; SelectContinuation(){} template <typename... Args> SelectContinuation(Args... args) : indexes{ args... } { } }; |
To be able to call select function in concurrent manner let’s add alias:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
template <typename R, typename... Args, typename... Sources, typename... Options> std::function<vector<R>(const SelectContinuation& job)> select_concurrent( const std::function<R(Args...)>& f, ///< output expression const std::tuple<Sources...>& sources, ///< list of sources const std::function<bool(Args...)>& filter, ///< composition of filters const Options&... options ///< other options and flags ) { return to_fn([=](const SelectContinuation& job){ return select(f, sources, filter, job, options...); }); } // optional #define CONCURRENTSELECT(X) select_concurrent(to_fn(X), |
That’s all! Next is the example how run select concurrently:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
// concurrent test SelectContinuation job1(0); SelectContinuation job2(100); auto get = CONCURRENTSELECT([](int& x){ return x; }) FROM(Naturals(1,200)) WHERE([](int& x){ return x % 2 == 0; }) LIMIT(10); // two async threads auto part1 = std::async(std::launch::async, [&](){ return get(job1); }); auto part2 = std::async(std::launch::async, [&](){ return get(job2); }); part1.wait(); part2.wait(); print(part1.get()); print(part2.get()); // Result: // 10 numbers: 2 4 6 8 10 12 14 16 18 20 // 10 numbers: 102 104 106 108 110 112 114 116 118 120 |
This approach can be extended to support additional border conditions and automatic split into parts.
You also could implement implicit concurrency inside main iterations of list comprehension by splitting upper cycle into several equal parts.
CONCLUSION
It’s possible to implement list comprehension in C++11 without using LINQ or similar libs. It will not be haskell-short but still you can gain some profits from it, as more readable and maintainable code in some cases and so on. Combined with custom self-defined additional options you can make such declaration even more profitable.
Lazy and concurrent evaluation could be added with no big effort.
But be aware of inner implementation – as there can be cases when naive list comprehension can lead to high cpu-consumption. Also in some cases list comprehension can have longer declaration than other ways of functional processing possible in modern C++ (like the one discussed here).
If you don’t like SQL syntax or macros you can still use list comprehension as function without any macro. If you invent more short names for options, add short function from() which will just make tuple from arguments, you can already use it like:
|
1 2 |
// without macro select(to_fn([](int x,int y){ return x + y; }), from(ints, ints), where([](int x, int y){ return x+y<10; }), limit(10)); |
and it’s also possible to get rid of to_fn() there.
Working example can be found on ideone / gist
APPENDIX: LOGIC OPERATIONS OVER FUNCTION LIST (OPTIONAL)
We could pass filters just as vector of functions slightly changing ‘checking’ part of cycle, so the next part is totally optional. But the following code might be useful somewhere else.
This part contains two functions: fn_compose(…) and fn_logic_add(…).
The first one is making normal mathematical composition: if you have input functions f1(),f2(),f3() it will return f(..) = f3(f2(f1(..))).
fn_logic_add will return f(..) = f1(..) && f2(..) && f3(..) as single std::function. Of cause, all input functions should have the same list of arguments and bool return type. This can be considered as logical and operation over the list of functions.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 |
template <typename F1, typename F2> struct function_composition_traits : public function_composition_traits<decltype(&F1::operator()), decltype(&F2::operator())> {}; template <typename ClassType1, typename ReturnType1, typename... Args1, typename ClassType2, typename ReturnType2, typename... Args2> struct function_composition_traits<ReturnType1(ClassType1::*)(Args1...) const, ReturnType2(ClassType2::*)(Args2...) const> { typedef std::function<ReturnType2(Args1...)> composition; typedef std::function<bool(Args1...)> boolOperation; template <typename Func1, typename Func2> inline static composition compose(const Func1& f1, const Func2& f2) { return [f1,f2](Args1... args) -> ReturnType2 { return f2(f1(std::forward<Args1>(args)...)); }; } template <typename Func1, typename Func2> inline static boolOperation logic_and(const Func1& f1, const Func2& f2) { return [f1,f2](Args1... args) -> bool { return f1(std::forward<Args1>(args)...) && f2(std::forward<Args1>(args)...); }; } }; // fn_compose template <typename F1, typename F2> typename function_composition_traits<F1,F2>::composition fn_compose(const F1& lambda1,const F2& lambda2) { return function_composition_traits<F1,F2>::template compose<F1,F2>(lambda1, lambda2); } template <typename F, typename... Fs> auto fn_compose(F f, Fs... fs) -> decltype(fn_compose(f, fn_compose(fs...))) { return fn_compose(f, fn_compose(std::forward<Fs>(fs)...)); } // fn_logic_and template <typename F1, typename F2> typename function_composition_traits<F1,F2>::boolOperation fn_logic_and(const F1& lambda1,const F2& lambda2) { return function_composition_traits<F1,F2>::template logic_and<F1,F2>(lambda1, lambda2); } template <typename F, typename... Fs> auto fn_logic_and(F f, Fs... fs) -> decltype(fn_logic_and(f, fn_logic_and(fs...))) { return fn_logic_and(f, fn_logic_and(std::forward<Fs>(fs)...)); } template <typename F> auto fn_logic_and(F f) -> decltype(to_fn(f)) { return to_fn(f); } |
This can be extended to support wide range of other operations over the list of functors. As soon as i expand it to size of some considerable value i will publish this part coupled with other additional handy conversion functions as tiny lib or something on github.
Any thoughts and corrections are welcome at comments.