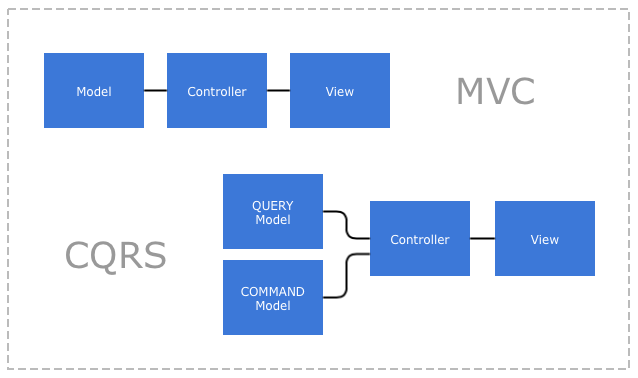
This is an example how to create continuation-like monadic behaviour in C++11 (encapsulate async execution) which is used for specific example: writing asynchronous scripts for system of distributed autotests.

I needed to add autotests into continuous integration of client-side multiplatform product. Basic way to build autotesting system is to grab one of well-known frameworks (especially if we are talking about web solutions) and test product locally. Local testing environment simulates clicks buttons inside UI and gets the results right away. This is simple and good way except the case when you have truly cross-platform solution (win, mac, web, iOS, android, etc), custom rich UI framework and you want to perform tests on various kinds of systems at same time.
So I came up with remote distributed scheme for autotests. And inside this post there are some ways to make this scheme shine.
This post contains 3 main points:
- what is distributed system of autotests and why the one would need it (advantages / disadvantages)
- how to implement asynchronous scenarios of distributed autotests using continuation monadic style in C++11/14 (how to encapsulate asynchronous execution and do this the most compact way)
- how to integrate ChaiScript scripting into such system to make it more flexible